오늘은 IDL에서 널리 사용되는 함수들 중 하나인 BYTSCL 함수에 관하여 살펴보고자 합니다. 이 함수의 역할은 그 명칭에서도 대략 짐작이 가능한데요. 바로 바이트 스케일링(Byte Scaling)입니다. 기본적으로는 다수의 값들로 구성된 배열에 대하여 최소값 및 최대값의 범위를 기반으로 모든 값들을 0~255 사이의 범위로 재조정하는 처리를 의미합니다. 즉 배열 내 모든 값들을 일괄적으로 0~255의 바이트스케일(Byte Scale)로 환산하는 역할이라고 볼 수 있습니다. 일단 IDL 도움말에서 BYTSCL 함수에 관한 내용을 찾아보면 사용 문법이 다음과 같이 명시되어 있습니다.
Result = BYTSCL( Array [, MAX=value] [, MIN=value] [, /NAN] [, TOP=value] )
실제로 도움말의 구체적인 내용을 살펴보면 BYTSCL 함수는 배열을 인수로 받게 되어 있습니다. 그 외에 몇가지 키워드들이 지원되고 있습니다. 그러면 일단 예제 배열을 하나 생성하여 BYTSCL 함수의 기능에 관하여 살펴봅시다. 예제로 사용할 배열은 다음과 같이 정의합니다.
a = [3, 6, 14, 17, 8, 10]
이와 같이 6개의 값들로 정의된 배열 a에 대하여 BYTSCL 함수를 적용하여 결과를 얻는 예제들을 지금부터 살펴볼텐데, 여기서는 세가지 경우들로 나눠서 소개하고자 합니다.
< 1 > BYTSCL 함수만 사용하는 경우
다음과 같이 배열 a에 대하여 BYTSCL 함수를 적용하여 a_scl이라는 결과를 얻어봅시다. 이 때 다른 키워드들은 전혀 사용하지않고 오롯이 BYTSCL 함수만 사용하는 경우입니다.
a_scl = BYTSCL(a)
PRINT, a_scl
출력된 a_scl의 값들은 다음과 같습니다.
0 54 201 255 91 127
이와 같은 결과가 산출되는 원리 및 과정은 다음과 같습니다.
(1) 배열 a의 최소값 및 최대값을 찾는다 (여기서는 3과 17)
(2) 배열 a의 값 범위인 3~17을 0~255로 변환한다
(3) 이 과정에서 배열 a의 모든 값들에 대한 3~17 범위 내에서의 위치를 0~255 범위 내에서의 위치로 환산한다
(4) 환산된 값들을 결과로 돌려준다
대략 이러한 과정을 거친다고 보면 됩니다. 이러한 원리를 도식적으로 설명한다면 다음 그림과 같습니다.

일단 여기까지는 BYTSCL 함수를 사용하면서 다른 키워드들은 전혀 사용하지 않은 경우입니다.
< 2 > BYTSCL 함수와 MIN, MAX 키워드를 함께 사용하는 경우
그러면 이번에는 BYTSCL 함수를 사용하면서 MIN, MAX 키워드들도 함께 사용해보겠습니다. MIN, MAX 키워드의 역할은 바이트 스케일링을 하는데 있어서 원본 데이터에 대하여 고려되는 범위에 대한 최소값 및 최대값을 유저가 직접 지정하는 것입니다. 만약 이 키워드들을 사용하지 않을 경우에는 디폴트 값으로 처리되는데, MIN 키워드의 디폴트 값은 원래 데이터 배열(여기서는 a)의 최소값이 되고 MAX 키워드의 디폴트 값은 원래 데이터 배열의 최대값이 됩니다. 그러면 여기서는 MIN, MAX 키워드의 값을 다음과 같이 0 및 20으로 설정해봅시다.
a_scl = BYTSCL(a, MIN=0, MAX=20)
PRINT, a_scl
출력된 a_scl의 값들은 다음과 같습니다. 앞서 MIN, MAX 키워드를 전혀 사용하지 않았던 경우와는 값들이 분명히 다르다는 것을 확인할 수 있습니다.
38 76 179 217 102 127
이와 같은 결과가 산출되는 원리 및 과정은 다음과 같습니다.
(1) 배열 a의 값들을 0~20 범위를 기준으로 가늠한다
(2) 배열 a의 모든 값들의 0~20 범위 내에서의 위치를 0~255 범위 내 위치로 환산한다
(3) 환산된 값들을 결과로 돌려준다
대략 이러한 과정을 거친다고 보면 됩니다. 이러한 원리를 도식적으로 설명한다면 다음 그림과 같습니다.

그러므로 만약 MIN, MAX 키워드의 값을 변경한다면 그 결과는 매번 달라지게 된다는 것은 쉽게 짐작할 수 있을 것입니다. 예를 들어서 MIN 키워드의 값을 0 그리고 MAX 키워드의 값을 60으로 설정하는 경우라면 그 결과는 다음과 같습니다.
a_scl = BYTSCL(a, MIN=0, MAX=60)
PRINT, a_scl
12 25 59 72 34 42

즉 배열 a의 값들은 3~17의 범위이지만 바이트 스케일링 과정에서 기준 범위를 0~60으로 설정하였기 때문에 값들이 전반부에 주로 분포하기 때문에 위와 같은 결과를 얻게 됩니다. 그리고 만약 MIN 키워드의 값을 -20 그리고 MAX 키워드의 값을 20으로 설정하는 경우도 살펴본다면 그 결과는 다음과 같습니다.
a_scl = BYTSCL(a, MIN=-20, MAX=20)
PRINT, a_scl
147 166 217 236 179 191

이것은 배열 a의 값들은 3~17의 범위이지만 바이트 스케일링 과정에서 기준 범위를 -20~20으로 설정하였기 때문에 값들이 주로 후반부에 분포하는 모습으로 결과가 얻어진 것입니다. 이와 같이 BYTSCL 함수로 바이트 스케일링 처리를 하는데 있어서 MIN, MAX 키워드를 사용하여 기준 범위를 유저의 필요에 따라 설정할 수 있다는 것을 유념해야 합니다.
< 3 > BYTSCL 함수와 TOP 키워드를 함께 사용하는 경우
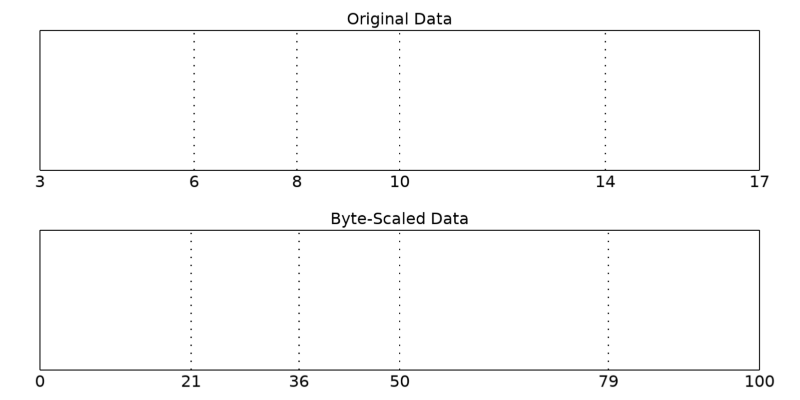
이번에는 BYTSCL 함수를 TOP 키워드를 함께 사용해보겠습니다. 이 TOP 키워드의 역할은 바이트 스케일링 처리가 완료된 결과값들의 범위에 대한 최대값을 별도로 설정하는 것입니다. 원래 TOP 키워드의 디폴트 값은 255입니다. 즉 바이트 스케일링을 거친 결과는 기본적으로는 0~255의 범위를 갖게 되는 것이 기본입니다. 하지만 만약 TOP 키워드에 전혀 다른 값 즉 예를 들어 100이란 값을 부여하면 최종 결과는 0~100의 범위를 갖게 됩니다. 사실 바이트 스케일링(Byte Scaling)이란 용어의 원래 의미가 대상 데이터를 0~255의 범위로 재조정한다는 뜻인데, TOP 키워드를 사용하면 결과의 상한값이 255가 아닌 다른 값이 되도록 하는 것도 가능하다고 보면 됩니다. 그러면 앞서 <1>에서 했던 작업을 다음과 같이 TOP 키워드만 추가하여 다시 실행해봅시다.
a_scl = BYTSCL(a, TOP=100)
PRINT, a_scl
출력된 a_scl의 값들은 다음과 같습니다.
0 21 79 100 36 50
이와 같은 결과가 산출되는 원리 및 과정은 다음과 같습니다.
(1) 배열 a의 최소값 및 최대값을 찾는다 (여기서는 3과 17)
(2) 배열 a의 값 범위인 3~17을 0~100으로 변환한다
(3) 이 과정에서 배열 a의 모든 값들의 3~17 범위 내에서의 위치를 0~100 범위 내 위치로 환산한다
(4) 환산된 값들을 결과로 돌려준다
즉 앞서 <1>의 경우와 비교하면 최종 결과의 상한값이 255가 아닌 100이 된다는 차이만 있다고 보면 됩니다. 이러한 원리를 도식적으로 설명한다면 다음 그림과 같습니다.
< 4 > BYTSCL 함수와 MIN, MAX, TOP 키워드를 모두 함께 사용하는 경우
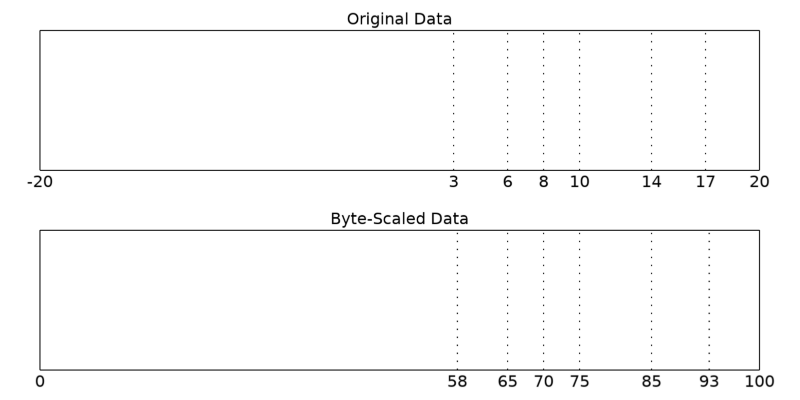
이제 BYTSCL 함수에서 지원되는 MIN, MAX, TOP 키워드들의 역할을 모두 이해했다고 가정하고 이 키워드들을 모두 함께 사용해봅시다. 그 예제는 다음과 같습니다.
a_scl = BYTSCL(a, MIN=-20, MAX=20, TOP=100)
PRINT, a_scl
58 65 85 93 70 75
이와 같이 MIN 키워드의 값을 -20 그리고 MAX 키워드의 값을 20으로 설정하여 배열 a의 값들을 처리하는 기준 범위가 -20~20이 되도록 함과 동시에 TOP 키워드의 값을 100으로 설정하여 최종 결과의 범위가 0~100이 되도록 하였습니다. 출력된 결과값들을 보면 이러한 기준에 의하여 산출되었음을 확인할 수 있습니다. 이러한 처리 과정을 도식적으로 설명한다면 다음 그림과 같습니다.
'IDL > 배열 생성 및 처리' 카테고리의 다른 글
| 배열 내 특정 값들의 탐색 (0) | 2024.06.11 |
|---|---|
| ARRAY_INDICES 함수의 필요성 (1) | 2024.02.14 |
| 원소값들을 직접 표기하여 배열을 생성하는 법 (3차원까지) (0) | 2023.11.29 |
| 배열 내 값들에 대한 샘플링(Sampling) (4) | 2023.05.26 |
| 배열 합치기(Array Concatenation) [2] (0) | 2023.04.18 |